Technologie-Deep-Dive · März 2026
Wie KI-Lip-Sync wirklich funktioniert: Von Phonemen zu Pixeln
Die Technologie, die einen deutschen Sprecher fließend Japanisch sprechen lässt — von Grund auf erklärt. Keine Buzzwords, nur die tatsächliche Wissenschaft.
Wenn Sie ein professionell synchronisiertes Video sehen und die Lippen des Sprechers perfekt zum übersetzten Audio passen, sehen Sie das Ergebnis eines der komplexesten Probleme der Computer Vision: die Generierung fotorealistischer Gesichtsbewegungen, die zu Sprache in einer Sprache passen, die der Sprecher nie tatsächlich gesprochen hat.
Der Qualitätsunterschied zwischen Plattformen — wo ein Tool native wirkende Ergebnisse liefert und ein anderes sichtbar fehlerhafte Mundbewegungen produziert — lässt sich darauf zurückführen, wie jedes System dieses Problem löst. Das Verständnis der Technologie erklärt, warum diese Unterschiede existieren.
Die Grundlage: Phoneme und Viseme
Jede gesprochene Sprache besteht aus Phonemen — den kleinsten bedeutungsunterscheidenden Lauteinheiten. Englisch hat etwa 44 Phoneme. Mandarin-Chinesisch hat ein anderes Set, einschließlich tonaler Variationen, die im Englischen fehlen. Arabisch hat pharyngale Laute, die Mundformen erzeugen, die englische Sprecher nie bilden.
Viseme sind die visuellen Gegenstücke — die Mundformen, die man beim Sprechen sieht. Entscheidend ist, dass es weniger Viseme als Phoneme gibt, da mehrere verschiedene Laute auf den Lippen identisch aussehen. Die Laute /p/, /b/ und /m/ erzeugen denselben bilabialen Verschluss — die Lippen pressen sich auf dieselbe Weise zusammen bei „pat", „bat" und „mat".
| Visem-Gruppe | Phoneme | Mundform | Beispielwörter |
|---|---|---|---|
| Bilabial | /p/, /b/, /m/ | Lippen zusammengepresst | pat, bat, mat |
| Labiodental | /f/, /v/ | Obere Zähne auf Unterlippe | fan, van |
| Dental | /θ/, /ð/ | Zunge zwischen den Zähnen | think, the |
| Offener Vokal | /ɑː/, /æ/ | Kiefer gesenkt, Mund weit | father, cat |
| Gerundeter Vokal | /uː/, /oʊ/ | Lippen nach vorne gerundet | boot, go |
Diese Phonem-zu-Visem-Zuordnung ist die erste Herausforderung beim Lip-Sync. Wenn das System übersetztes Audio auf Japanisch erhält, muss es identifizieren, welche Phoneme gesprochen werden, sie den richtigen Visemen zuordnen und dann die entsprechenden Mundformen auf dem Gesicht des Original-Sprechers generieren — und dabei Identität, Hautstruktur, Beleuchtung und Kopfposition beibehalten.
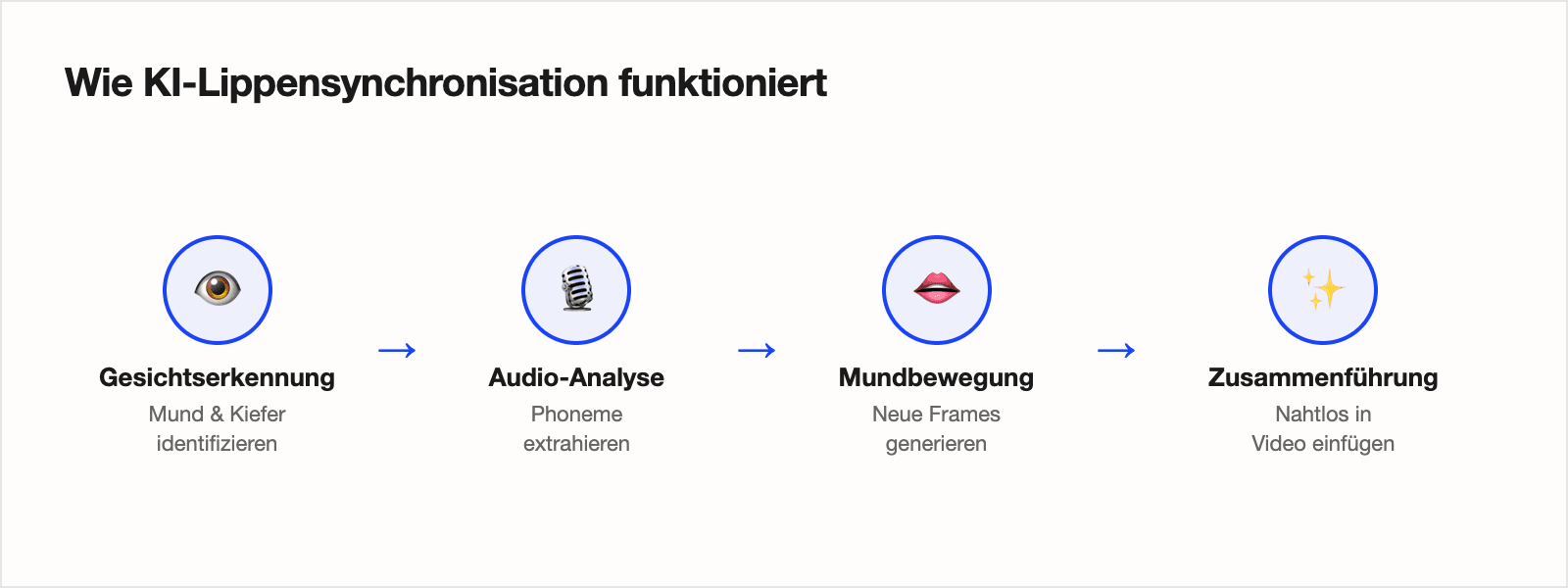
Die KI-Lip-Sync-Pipeline: Vier Schritte
Moderne Lip-Sync-Systeme verarbeiten Video in vier Stufen. Das Verständnis dieser Stufen erklärt, warum manche Tools schwieriges Filmmaterial (Verdeckungen, mehrere Sprecher, schnelle Bewegungen) besser verarbeiten als andere.
Gesichtserkennung & Landmark-Mapping
Das System identifiziert alle Gesichter im Frame und kartiert 68–468 Gesichtslandmarken — die präzisen Koordinaten von Augen, Nase, Kieferlinie und vor allem die Lippenkontur. Dies geschieht in jedem einzelnen Frame. Bei einem 30fps-Video sind das 1.800 Landmark-Erkennungen pro Minute Filmmaterial.
Audio-Analyse & Phonem-Extraktion
Das übersetzte Audio wird in ein Mel-Spectrogram umgewandelt — eine visuelle Darstellung des Frequenzinhalts des Audios über die Zeit. Der Speech Encoder verarbeitet dies, um das Phonem-Timing zu extrahieren: genau wann jeder Laut beginnt und endet, auf die Millisekunde genau.
Mundbereich-Generierung
Hier findet die eigentliche Synthese statt. Ein generatives Modell (typischerweise ein GAN oder Diffusion Model) nimmt die Gesichtslandmarken + Phonemdaten und generiert neue Pixelwerte für den Mundbereich. Die obere Hälfte des Originalgesichts bleibt erhalten; nur die untere Gesichtshälfte wird neu generiert.
Blending & temporale Glättung
Der generierte Mundbereich wird zurück in den Originalframe eingeblendet. Kantenartefakte müssen eliminiert, Hauttöne müssen übereinstimmen und temporale Konsistenz muss gewährleistet sein — das Gesicht darf nicht zwischen Frames flackern oder sich verschieben.
Die Modelle, die es möglich machten
Wav2Lip (2020)
Wav2Lip, veröffentlicht auf der ACM Multimedia 2020 von Forschern des IIIT Hyderabad, war der Durchbruch, der praktikables Lip-Sync auf beliebigen Gesichtern ermöglichte. Die Schlüsselinnovation: ein vortrainierter „Lip-Sync-Expert"-Discriminator, der bewertet, ob die generierten Mundbewegungen tatsächlich zum Audio passen.
Die Architektur hat drei Komponenten: einen Identity Encoder (erfasst das Gesicht des Sprechers mittels gestapelter residualer Convolutional Layers), einen Speech Encoder (verarbeitet Mel-Spectrograms zu Speech Embeddings) und einen Face Decoder (Transpose Convolutional Layers, die den Ausgabe-Frame generieren). Das Modell maskiert während des Trainings die untere Hälfte des Eingabegesichts und zwingt es so, Lippenbewegungen ausschließlich aus Audio zu lernen.
GANs und Adversarial Training
Generative Adversarial Networks (GANs) sind das Rückgrat der meisten aktuellen Lip-Sync-Systeme. Zwei neuronale Netzwerke konkurrieren: Der Generator erzeugt synthetische Mundregionen, und der Discriminator versucht, echte von generierten Frames zu unterscheiden. Dieser adversariale Prozess treibt den Generator zu immer fotorealistischeren Ergebnissen.
Wav2Lip-HQ erweiterte das Originalmodell durch Face Parsing (Segmentierung des Gesichts in Bereiche für präzisere Bearbeitung) und Super-Resolution (Hochskalierung der generierten Region auf die Auflösung des Originalvideos). Dies behob eine der Haupteinschränkungen von Wav2Lip: Die generierte Mundregion war oft merklich unschärfer als das umgebende Gesicht.
Diffusion Models (2024–2026)
Die neueste Generation von Lip-Sync-Systemen verwendet Diffusion Models — dieselbe Architektur-Familie, die hinter Bildgeneratoren wie Stable Diffusion steckt. Modelle wie VividTalk und MoDiT nutzen 3D Morphable Face Models in Kombination mit Diffusion Transformers und verwenden Wav2Lip-Output als Motion Prior, der zu höherer Qualität verfeinert wird. Diese Ansätze liefern temporal konsistentere Ergebnisse mit weniger Artefakten, besonders bei komplexem Filmmaterial mit Kopfbewegungen und teilweisen Verdeckungen.
Warum sich die Qualität zwischen Plattformen so dramatisch unterscheidet
Dieselbe zugrunde liegende Forschung steht jedem Unternehmen zur Verfügung. Der Unterschied in der Ausgabequalität ergibt sich aus Engineering-Entscheidungen, die sich kumulieren:
| Herausforderung | Was schiefgeht | Wie die besten Systeme damit umgehen |
|---|---|---|
| Verdeckungen | Hände, Mikrofone oder Brillen verdecken den Mund | Temporale Vorhersage: Mundform aus umliegenden Frames + Audio ableiten, verdeckte Pixel auffüllen |
| Profilaufnahmen | Nur teilweise sichtbare Lippen bei steilen Winkeln | 3D-Gesichtsmodell-Rekonstruktion: das Gesicht in 3D verstehen, korrekte Perspektive generieren |
| Mehrere Sprecher | Mehrere Gesichter, jedes spricht anderes Audio | Speaker Diarization + Gesichtstracking: jede Stimme automatisch dem richtigen Gesicht zuordnen |
| Schnelle Bewegung | Kopfdrehungen, Gesten lassen Landmark-Tracking abdriften | Optical-Flow-Stabilisierung: Gesicht als starren Körper durch die Bewegung tracken, Landmarks re-projizieren |
| Auflösungs-Diskrepanz | Generierter Mundbereich wirkt unscharf oder künstlich glatt | Super-Resolution + Textur-Transfer: Textur der generierten Region an die originale Haut anpassen |
| Temporales Flickern | Frame-für-Frame-Generierung verursacht sichtbares Zittern | Temporaler Discriminator: zusätzliche GAN-Komponente, die Inkonsistenz über Frames bestraft |
Plattformen, die von Grund auf speziell für das Dubbing realer Aufnahmen entwickelt wurden, haben in der Regel mehr in diese Randfälle investiert als Plattformen, die mit Avatar-Synthese begonnen und später Dubbing realer Aufnahmen hinzugefügt haben. Das Avatar-Problem ist grundlegend einfacher — man kontrolliert die Beleuchtung, die Gesichtsgeometrie und den Kamerawinkel. Bei realen Aufnahmen gibt es keine dieser Garantien.
Über Dubbing hinaus: Wo Lip-Sync-Technologie eingesetzt wird
Video-Dubbing ist die sichtbarste Anwendung, aber dieselbe Kerntechnologie treibt auch Folgendes an:
- →Film- und TV-Postproduktion
— Korrektur von Dialogen in Szenen, in denen das Originalaudio unbrauchbar war, ohne dass Schauspieler für ADR (Automated Dialogue Replacement) zurückkehren müssen.
- →Barrierefreiheit
— Generierung von Gebärdensprach-Avataren, die übersetzte Inhalte mit präzisen Lippenbewegungen für hörgeschädigte Zuschauer sprechen.
- →Gaming und VR
— Echtzeit-Lip-Sync für NPC-Dialoge. Technologien wie Metas OVR Lip Sync verarbeiten Audio mit 100fps und geben Visem-Gewichtungen für Game-Engine-Charaktere aus (Meta Developer Docs).
- →Videokonferenzen
— NVIDIAs Audio2Face generiert Gesichtsanimationen aus Audio in Echtzeit mittels 52 ARKit Blend Shapes und ermöglicht so Videogespräche mit niedriger Bandbreite, bei denen nur Audio übertragen und das Gesicht clientseitig rekonstruiert wird.
Die Ethik-Frage
Dieselbe Technologie, die es einem CEO ermöglicht, Mitarbeiter in 38 Sprachen anzusprechen, kann dazu verwendet werden, jemandem Worte in den Mund zu legen, die er nie gesagt hat. Die Deepfake-Bedenken sind real und verdienen eine direkte Auseinandersetzung.
Verantwortungsvolle Plattformen begegnen dem durch Einwilligungsprüfung (Nachweis, dass man die Rechte am Filmmaterial hat), Wasserzeichen (Einbettung unsichtbarer Markierungen im generierten Video) und Audit-Trails (Protokollierung, wer welchen Inhalt verarbeitet hat). DSGVO-konforme Plattformen fügen eine weitere Ebene hinzu: Das Originalfilmmaterial und die generierte Ausgabe müssen unter demselben Datenschutzrahmen verarbeitet und gespeichert werden.
Die Technologie selbst ist neutral. Der Unterschied liegt in der Governance — wer Zugang hat, welche Schutzmaßnahmen existieren und ob die Plattform Videoinhalte als personenbezogene Daten behandelt (was sie nach EU-Recht sind, wenn sie identifizierbare Gesichter enthalten).
Vergleichen Sie jetzt die Tools, die diese Technologie nutzen
Sehen Sie, wie verschiedene Plattformen diese Techniken anwenden — und wo jede einzelne glänzt oder Schwächen zeigt.
Quellen
- A Lip Sync Expert Is All You Need for Speech to Lip Generation In the Wild — Prajwal et al., ACM Multimedia 2020. Das Wav2Lip-Paper.
- Can One Model Fit All? Wav2Lip's Lip-Syncing Generalizability Across Languages — Springer, 2024. Sprachübergreifende Evaluation.
- Perceptual Synchronization Scoring Using Phoneme-Viseme Agreement — Gupta et al., WACV 2024. Benchmarking-Methodik.
- Lip Syncing AI Characters: Techniques and Future Trends — Convai, 2025. Branchenübersicht.
- Viseme — Wikipedia. Grundlegende Definitionen.
- Phoneme — Wikipedia. Grundlegende Definitionen.
Häufig gestellte Fragen
Was ist KI-Lip-Sync?
KI-Lip-Sync ist eine Technologie, die Deep Learning nutzt, um die sichtbaren Mund- und Gesichtsbewegungen eines Sprechers im Video so zu verändern, dass sie zu Audio in einer anderen Sprache passen. Das System analysiert das Originalgesicht Frame für Frame, kartiert Gesichtslandmarken und generiert dann neue Mundbewegungen, die zu den Phonemen des übersetzten Audios passen. Moderne Systeme verwenden Generative Adversarial Networks (GANs) und Diffusion Models, um fotorealistische Ergebnisse zu erzielen.
Was ist der Unterschied zwischen Visemen und Phonemen?
Phoneme sind die kleinsten bedeutungsunterscheidenden Lauteinheiten einer Sprache — Englisch hat etwa 44 Phoneme. Viseme sind die visuellen Mundformen, die diesen Lauten entsprechen. Es gibt weniger Viseme als Phoneme, da mehrere verschiedene Laute auf den Lippen identisch aussehen (zum Beispiel erzeugen 'p', 'b' und 'm' denselben bilabialen Verschluss). KI-Lip-Sync-Systeme müssen Audio-Phoneme den richtigen visuellen Visemen zuordnen, um überzeugende Mundbewegungen zu erzeugen.
Was ist Wav2Lip und wie funktioniert es?
Wav2Lip ist ein grundlegendes KI-Modell für Lippensynchronisation, veröffentlicht auf der ACM Multimedia 2020 von Forschern des IIIT Hyderabad. Es verwendet eine Encoder-Decoder-Architektur mit drei Komponenten: einem Identity Encoder, der die Gesichtsstruktur des Sprechers erfasst, einem Speech Encoder, der Audio-Mel-Spectrograms verarbeitet, und einem Face Decoder, der neue Mundbewegungen generiert. Ein vortrainierter Lip-Sync-Discriminator stellt die audio-visuelle Übereinstimmung sicher. Wav2Lip funktioniert mit beliebigen Gesichtern und Audiodateien und eignet sich daher effektiv für das Dubbing realer Aufnahmen.
Warum variiert die Lip-Sync-Qualität zwischen KI-Dubbing-Tools so stark?
Die Qualität hängt von der zugrunde liegenden Modellarchitektur, den Trainingsdaten und dem Engineering-Fokus ab. Avatar-first-Plattformen haben ihr Lip-Sync auf synthetischen Gesichtern trainiert, was ein grundlegend anderes Problem ist als die Synchronisation realer menschlicher Aufnahmen. Wichtige Differenzierungsmerkmale sind Occlusion Handling (was passiert, wenn Hände das Gesicht verdecken), Multi-Speaker-Erkennung, temporale Konsistenz (kein Flickern zwischen Frames) und die Auflösung der generierten Gesichtsregion. Plattformen, die speziell für Video-Dubbing entwickelt wurden, übertreffen in der Regel solche, die Dubbing als Sekundärfunktion hinzugefügt haben.
Kann KI-Lip-Sync mehrere Sprachen verarbeiten?
Ja, aber mit unterschiedlicher Qualität. Verschiedene Sprachen haben unterschiedliche Phonem-Inventare und damit unterschiedliche Visem-Zuordnungen. Englisch hat etwa 44 Phoneme; Mandarin-Chinesisch hat andere tonale Eigenschaften, die die Mundform beeinflussen. Die besten Systeme verwenden sprachspezifische Phonem-zu-Visem-Zuordnungen, die mit Linguisten entwickelt wurden. Systeme, die ein einziges universelles Modell für alle Sprachen verwenden, erzeugen tendenziell weniger präzise Mundbewegungen für nicht-englische Inhalte.
Sources & Further Reading
- How AI Dubbing Is Reshaping Global Media — Slator, 2025
- AI dubbing in 2026: the complete guide — RWS, 2026
- AI Dubbing 2025: How Technology is Transforming Video Localization — Speeek, 2025